
Computer vision is at the heart of some of the most exciting emerging technologies today. Think about self-driving cars, conservational animal tagging, diagnostic imaging, or the ubiquity of facial recognition unlocking our phones; behind all of this innovation is computer vision.
Alas, computer vision requires image annotation which can be a painstaking, laborious task and pose serious problems if done improperly. This means there are fantastic opportunities arising in the tech professional landscape for developers who know about image annotation.
This article dives into the nuts and bolts of image annotation, breaking down what it is, why it’s so important, and the challenges developers face in making it work. We’ll cover different types of annotation, essential skills for developers, and recommend the general best practices for image annotation whatever computer vision model you’re working on.
An Introduction to Computer Vision and Image Annotation
For the layperson, computer vision is an application of machine learning (ML) models that enables computers to understand the world around them through visual information – in a sense, it teaches them to see.
Unsurprisingly, this innovation is reshaping industries and transforming our interactions with technology. Its applications span a wide array of domains, each harnessing the power of visual data to drive groundbreaking advancements. This is one of the reasons why learning ML is better for your career than traditional programming.
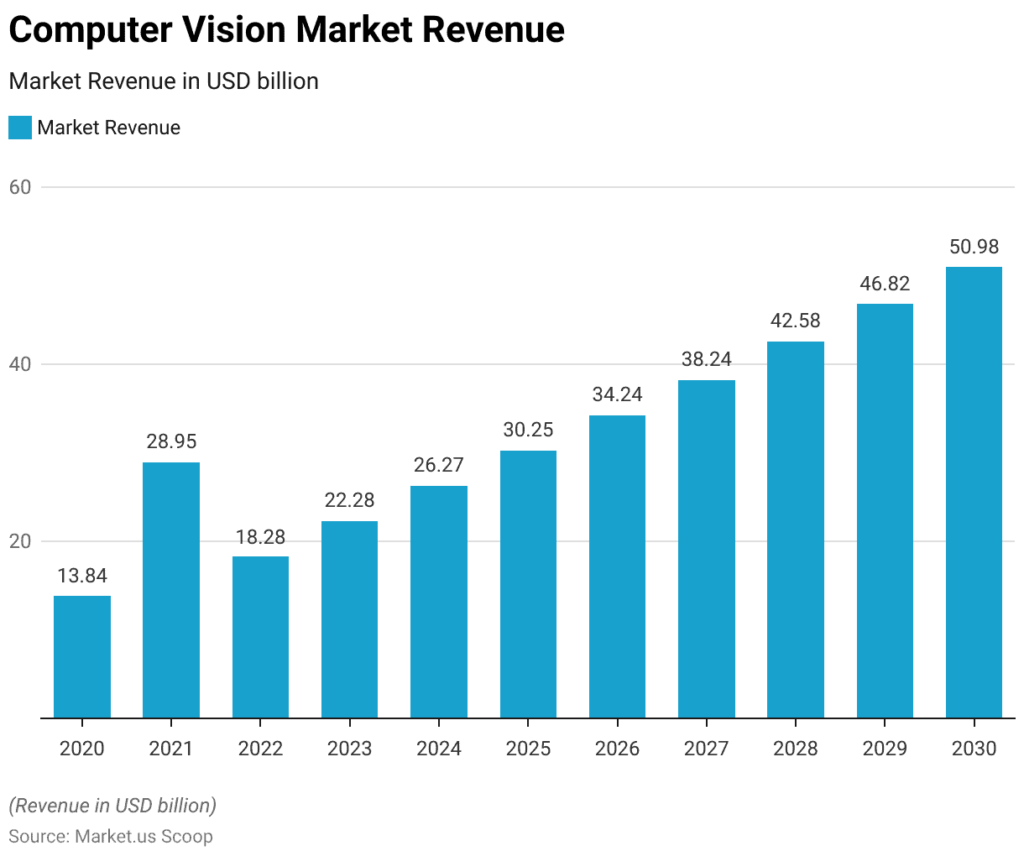
The Increasing Applications of Computer Vision
- Autonomous Vehicles: Autonomous vehicles perceive their surroundings by interpreting visual data from cameras and sensors. This is how tech is making autonomous cars safer than ever.
- Facial Recognition: Facial recognition technology has become ubiquitous, powering security features on smartphones, surveillance systems, and authentication mechanisms.
- Medical Imaging: In the realm of healthcare, computer vision plays a pivotal role in revolutionizing medical imaging techniques. From X-rays and MRIs to CT scans and ultrasounds, algorithms analyze image data to aid in disease diagnosis and treatment.
- Retail and Inventory Management: By deploying cameras and image recognition algorithms, retailers can track products on shelves and monitor stock levels in real-time. Personalized shopping experiences, augmented reality fitting rooms, and AI-powered customer service have also come to play a big role in the retail landscape.
- Conservation Efforts: Beyond commercial applications, computer vision contributes to vital conservation efforts offering a non-invasive solution to monitoring wildlife populations. Remote cameras equipped with image recognition technology enable researchers to gather valuable data for conservation initiatives.
The Role of Image Annotation in Computer Vision
All of these applications of computer vision rely on ML algorithms sifting through vast data sets. Crucially, for this data to be understood, it must be high quality, clean, and properly annotated. Understanding techniques like web crawling vs web scraping are instrumental in collecting diverse and extensive datasets from various sources, which are then refined and annotated for use in training ML models.
Image annotation is the process of enriching raw visual data with metadata and tags. It’s what enables AI systems to understand and interpret images by adding contextual information, spatial references, and semantic labels.
From drawing bounding boxes around objects to segmenting pixels and identifying key points, image annotation is how to bridge the gap between raw visual data and AI-driven insights.
Different Types of Image Annotation
Image annotation is a broad umbrella term that encompasses a diverse array of types, techniques, and processes, each tailored to specific tasks and objectives. By leveraging these annotation techniques, developers can train robust ML models capable of accurately interpreting and analyzing visual data.
Let’s delve deeper into each annotation type to understand its role in computer vision applications:
1. Bounding Boxes and Cuboids
Bounding boxes provide spatial annotations by enclosing objects within rectangular or cuboidal regions. This technique is essential for tasks like object detection and localization.
In an image of a street scene from CCTV cameras, bounding boxes could be used to outline and identify vehicles, pedestrians, and traffic signs. This enables AI systems to recognize and analyze the spatial relationships between objects.
2. Image Classification
Image classification involves associating entire images with predefined labels or categories. This technique trains models to recognize visual patterns and characteristics, enabling them to categorize images based on their content.

For instance, in a dataset of shark images, each image may be labeled with the corresponding species (“Great White,” “Bronze Whaler,” “Shortfin Mako,” etc.) allowing AI systems to classify images accurately.
(Free to use image from Pexels)
3. Lines, Splines, and Polylines
Annotating straight or curved lines aids in tasks such as road detection for autonomous vehicles and trajectory tracking for drones. In a satellite image of a road network, lines and splines can be used to delineate road boundaries, lanes, and intersections, providing crucial spatial information for navigation and path planning algorithms.
4. Polygons and Semantic Segmentation
Polygons offer precise delineation of object boundaries within images, while semantic segmentation assigns categorical labels to individual pixels. This technique enables fine-grained scene understanding by identifying and categorizing objects and regions within images.
One use of polygons is in doctors analyzing medical imaging. These models can be used to outline tumors or anatomical structures. Semantic segmentation can also be used to differentiate between different tissue types or organs, aiding in disease diagnosis and treatment planning.
6. Landmarking and Keypoint Annotation
Identifying keypoints or regions of interest within images facilitates tasks like facial recognition, pose estimation, and anatomical landmark detection. For instance, in a facial recognition system, keypoints can be used to identify and track facial features such as eyes, nose, and mouth, enabling accurate identification and analysis of facial expressions and gestures.
Another thing: what is CCaaS’s, social media’s, and education’s shared characteristic? They’re all investigating ways to use AI emotion and sentiment analysis with computer vision to better understand the emotions of their target audiences. Landmarking and keypoint annotation plays a key part in this process too.
Challenges in Image Annotation
Essentially there is one challenge of image annotation: maintaining quality, consistency, and accuracy of annotation across vast data sets. Producing clean annotated data is the only goal of image annotation; however there are a number of practical obstacles in achieving this goal.
Among these challenges, the management of proprietary data under stringent legal frameworks becomes critical. The use of a digital contract can ensure that all parties adhere to agreed standards of data handling and annotation, protecting intellectual property and complying with privacy regulations.
To address these challenges, many organizations are turning to a sophisticated product dashboard that provides real-time insights into annotation quality and process efficiency, ensuring that standards are met across vast datasets.
As such, the challenge of maintaining quality can manifest in many different ways. These are the key trouble zones you’ll need to focus on:
- Balancing Human and Automated Annotation – Achieving the right balance between human expertise and automated tools is crucial for optimizing annotation efficiency and accuracy. Leveraging automation for large-scale datasets while relying on human annotators for nuanced tasks ensures quality annotations.
- Skills and Expertise – Image annotation requires technical proficiency with specialized tools and domain-specific knowledge. Providing adequate training and supporting annotators to achieve data science qualifications ensures consistency and accuracy in annotations.
- Quality Control and Consistency – Image annotation requires a detailed plan with clear annotation instructions that are well communicated across dev teams. Implementing robust quality control measures like inter-annotator compliance audits, and consensus-based annotation, also helps maintain annotation accuracy and consistency across datasets.
Best Practices for Effective Image Annotation
When it comes to effective image annotation for computer vision projects, adopting best practices is essential to ensure accuracy, reliability, and efficiency.
1. Prioritize Human Annotation
Human annotation brings a level of expertise and contextual understanding that automated tools often lack. Human annotators can interpret complex visual data, recognize subtle nuances, and adapt to diverse annotation tasks.
By prioritizing human annotation, developers can ensure high-quality annotations that meet the specific requirements of their projects. Additionally, human annotators can provide valuable insights and feedback, contributing to the overall success of the annotation process.
2. Annotate Images Completely
As a rule of thumb, the more care and attention you can invest in annotation, the better your ML model will fare. Annotating images completely doesn’t just mean annotating every image either. It means ensuring that bounding boxes are tightly configured, labels are clear and consistent, and most importantly, that all objects of interest are tagged.
Failing to annotate all instances can hinder the model’s ability to accurately detect and classify objects. When annotating complex images with multiple objects, it’s essential to label all instances of each object category present in the image.
In scenarios where objects are partially obscured or occluded by other objects or elements, it’s crucial to accurately annotate the visible portions of the occluded objects too. This ensures that the model learns to recognize and differentiate occluded objects correctly, enhancing its robustness in real-world scenarios where occlusions are common.
3. Choose Reliable Annotation Tools
Selecting the right ML toolkit, specific annotation tools and platforms is paramount. Developers should evaluate annotation tools based on factors such as annotation types supported, scalability, ease of use, and collaboration features.
Reliable annotation tools often offer advanced features such as version control, real-time collaboration, and quality assurance mechanisms, enhancing productivity and accuracy throughout the annotation process. The chosen tools should align with the project’s requirements and facilitate efficient annotation workflows.
It’s also important to plan for possible transitions between annotation tools, so it’s a good idea to have an application migration strategy in place and ensure your annotation tools provide the required features.
Quality Image Annotation for Computer Vision: Conclusions
In conclusion, image annotation stands as a fundamental pillar of computer vision, enabling machines to perceive and understand the visual world. By understanding the diverse annotation techniques, addressing inherent challenges, and adopting best practices, developers can unlock the full potential of AI-powered image analysis.
The post A Guide to Understanding Quality Image Annotation for Computer Vision appeared first on Codemotion Magazine.