
Have you ever wondered whether your machine learning (ML) models are performing as well as they could be? There are plenty of factors that can impact their performance, skewing their results and negatively impacting the accuracy of their predictions.
If you want to improve their performance, then ML model debugging is the way forward.
Read on for a comprehensive overview of how to debug ML models, including common warning signs you should look for, and effective strategies you can employ.
What is ML Model Debugging?
As you’re probably aware, machine learning is a branch of artificial intelligence (AI) with many applications. Many organizations are adopting ML for a variety of use cases, from financial fraud prevention to part of their application modernization strategy.
Machine learning model debugging is the process of identifying and resolving issues, or ‘bugs’, within machine learning models that can affect their performance.
The Unique Challenges of ML Model Debugging
Debugging is a crucial part of the traditional software development process. It’s used to diagnose problems, trace their causes, and implement fixes to make sure that the final product performs as well as possible.
When it comes to ML debugging, however, things get a bit more complicated -you’ll likely need somebody with a data engineer certificate to run the process.
Data extraction plays a vital role in ML model debugging, as it involves retrieving and preparing relevant data for analysis and troubleshooting.
To start with, poor quality results from an ML model don’t necessarily indicate the presence of a ‘bug’ in the traditional sense. There’s a lot of potential causes, such as poor data quality or hyperparameters being set to nonoptimal values.
This means debugging ML models requires a deep understanding of the model, exploring a range of options, and running time-consuming experiments, leading to longer iteration cycles.
Read also: Top AI Certifications To Boost Your Career
Why debug machine learning models?
ML model debugging is crucial for a few reasons:
- Ensuring reliability. Debugging ML models helps assure developers of their reliability, increasing confidence in their predictions.
- Improving performance. Debugging can identify factors that negatively affect performance, enabling them to be fixed.
- Reducing bias. Data interpretation allows you to identify biases in ML models, which helps developers to mitigate them, improving the model overall.
- Saving time and resources. Bugs can be found earlier in development by carrying out consistent debugging, leading to more efficient iteration as time isn’t wasted on flawed models.
Common ML Model Bugs
Now that we understand the importance of ML model debugging, let’s examine some of the most common bugs that can affect the performance of ML models:
- Data quality. ML models require high quality data to produce reliable results, meaning incomplete or inaccurate data can throw off the whole model.
- Data leakage. Data from a test set or other source can be inadvertently included in the model’s training data, leading to compromised model reliability and skewed decision-making. This is known as data leakage.
- Deployment issues. Deployed models can exhibit unexpected behavior if there are stark differences between the development and deployment environments.
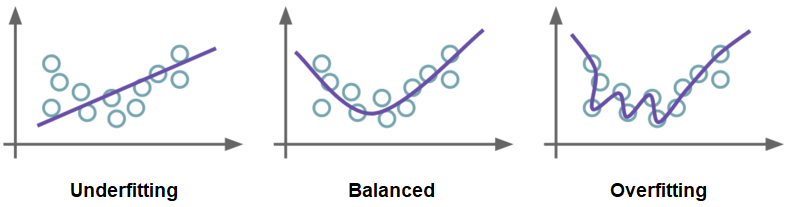
- Overfitting. Overfitting occurs when an ML model can give accurate predictions for training data, but not for new data. It’s caused when a model cannot generalize and fits too closely to the training dataset instead. This is usually due to the training data sample being too small or containing a lot of irrelevant information.
- Underfitting. Underfitting occurs when a model is too simple to capture the underlying complexities of data. This leads to poor performance on the training data and test data.
5 Steps for Successful ML Model Debugging
Now that you have a better idea of what kind of bugs you might be looking for, it’s time to think about the best way to rectify them. Here are five key steps for successful ML model debugging.
- Define expected behavior
Your first step should be to clearly define the expected behavior and performance metrics for your machine learning model. By doing this you can establish a benchmark that you can evaluate your model’s performance against to detect errors.
- Identify the error
Unsurprisingly, it’s hard to fix a bug that you don’t know exists. You should evaluate your trained model on a validation set to assess its performance.
There are other ways to locate errors in ML models, too. Performance monitoring can signpost potential errors for investigation, as can gathering user feedback and looking for common pain points.
- Locate the problem
Once you’re aware that there’s an error to be fixed, you need to narrow down exactly where it’s occurring.
You’ll first need to identify the datasets where the model performs poorly. How challenging this is will vary depending on the data model you’re using, (for our recommendation, see our Snowflake schema example). The more specific you can be, the greater chance you have of fixing the problem quickly.
Try breaking down the problem to identify specific regions of data where the model exhibits particularly poor performance. For example, data quality issues such as missing values or shifting data values could be causing a problem.
- Analyze the error
Once you’ve located the error, you can begin to analyze it. This is important for identifying potential knock-on issues that could affect other areas of the model, allowing you to more accurately estimate the risk that the error poses.
- Attempt fixes and monitor
Once you’ve fully identified the error and its implications, it’s time to rectify it. Techniques such as cross-validation, regularization, or data augmentation can all be used to fix errors and improve model performance.
Iterative improvement should be used through the debugging process, adjusting model parameters or training procedures based on the results of error analysis. It’s important to continuously monitor the model’s performance even after you’ve fixed the error, making adjustments as necessary if problems persist.
Common ML Debugging Strategies
There’s no ‘one-size-fits-all’ approach to ML model debugging, partly due to the sheer number of different types of machine learning models. There are multiple strategies you can deploy to fix errors in your application. Here are some of the most effective approaches you can take.
Outsourcing Software:
Outsourcing certain aspects of ML model debugging can also be a viable strategy, particularly for organizations lacking in-house expertise or resources. Outsourcing software and tapping into external expertise can provide fresh insights and accelerate the debugging process.
Residual analysis
Residual analysis is one of the most commonly used debugging methods among data scientists and developers. It involves assigning a numeric value to the difference between observed and predicted outcomes.
The predicted value is subtracted from the observed value in order to calculate the residual. This is a useful method for determining exactly where a model is wrong, and for assessing its reliability when making predictions based on unseen data.

Image created by author
Data augmentation
Data is crucial when it comes to ML. Data augmentation is used to supplement small datasets or correct missing data, adding new training samples where gaps exist in the dataset. It’s common in ML problems to have a training dataset that doesn’t contain every possible answer or parameter of an algorithm; data augmentation allows us to fill those gaps to improve the accuracy and predictive power of the model.
Benchmark models
You can compare your model against a benchmark model in order to assess its performance. A benchmark model is a model that’s proven to be reliable, transparent, and easy to use and interpret.
Comparing your model’s performance against that of a benchmark allows you to easily see whether the new model offers significant improvements when it comes to predictive accuracy, or other relevant metrics.
Benchmark models are typically easy to implement, and don’t take up too much time. They can also be used to predict how an ML model will perform on different data classes. For instance, if you find that your ML model is overfitting on some data, a benchmark model can help you understand whether or not it’s because the data is special in some way.
Sensitivity analysis
Sensitivity analysis – sometimes referred to as “what if” analysis – can show how a model will react to unseen data by observing what it predicts from given data. It achieves this by estimating how sensitive a model is to changes in the input parameters from their nominal values.
Models can be sensitive to changes in multiple input variables. By using sensitivity analysis, you can determine which input variables are causing the problem by studying multiple variables in depth at once.
Security audit
Machine learning models can be susceptible to attacks, but most commonly used assessment practices aren’t able to tell us if a model is safe or not.
Luckily, there are multiple ways to test the safety of ML models. It’s crucial to employ a cybersecurity framework that is capable of protecting your models from threats.
By implementing robust security measures, and integrating AI into your business, you can ensure the integrity and reliability of your machine learning solutions.
All of your data, documentation, and information should only be accessible to authorized members. It’s also important to make routine backups, and continually update all security measures to keep data secure.
Model editing and monitoring
It’s crucial to keep monitoring and managing your machine learning models, even if they seem to be working fine. Things can drastically change in the blink of an eye.
To track changes and identify where issues may have arisen, keep track of who trained the models, on what data, and when. Keeping records of all the datasets, inputs, and predictions is a big part of this. It’s always worth checking whether a model can be recalibrated and re-optimized.
Boost Your ML Models’ Performance by Debugging
Ensuring the optimal performance and reliability of machine learning models is crucial for their success, however you’re deploying them. ML model debugging is a core part of this. By systematically identifying and resolving issues, you can improve the accuracy, reliability, and fairness of your models, resulting in more trustworthy predictions.
There are a variety of ways to carry out ML model debugging, but the process should always be iterative to reflect the dynamic nature and continuous improvement cycle of the machine learning field. By embracing a systematic and multifaceted approach to debugging, developers can navigate the complexities of model development and deployment, unlocking the full potential of machine learning technologies in the process.
The post How to Debug ML Models to Boost Performance appeared first on Codemotion Magazine.